Tempdb configuration and performance
This is hardly a new topic and whilst there are a lot of articles out there instructing us on how to stripe tempdb etc I feel there’s a bit of a gap on exactly how to identify a problem with tempdb in the first place and particularly on finding out how much of your overall IO tempdb is responsible for.
I cover that in this post but it is also covered more extensively in my SQL Server and Disk IO series of posts, as the troubleshooting and monitoring principles covered in them are just as valid for tempdb performance monitoring as they are for application databases.
Also, as this is the concluding post in that series I could hardly avoid writing about it!
If an application database is poorly configured in terms of disk layout then generally only that database will be affected by e.g. queries utilising a lot of disk IO performing poorly. If tempdb is poorly configured in terms of disk layout the whole SQL Server instance will suffer performance problems for the simple reason that tempdb is effectively a workhorse database that does a lot of work in the background.
Some of this background work tempdb is obvious, some of it is not so obvious:
- temporary tables (explicitly created in queries/procs etc)
- queries that sort (order) data (temporary tables will be created under the covers to sort the data)
- worktable spools (when a query cannot be processed entirely in memory)
- Service Broker
- app databases utilising Snapshot Isolation (to hold versioned data)
- linked server queries
- SQL Server internal processes
This is by no means a complete list, and, in all likelihood, as features are added to SQL Server the list will grow rather than shrink.
One way of thinking about tempdb is that it’s like an OS swap file. When the OS runs out of memory the swap file becomes the default dumping ground and performance slows and in the same way a poorly sized and configured swap file can cripple a server a poorly configured tempdb will cripple SQL Server
The most common issue related to tempdb that every DBA will hit sooner or later is space usage when a runaway query maxes out tempdb and it runs out of space. Those kind of issues are pretty easy to solve and well documented all over the web; check out the links at the end of the post.
This post is going to focus more on the performance issues and they can usually be pinned down to the physical database design. If you’ve been reading the previous posts on this SQL Server and Disk IO series you’ll know how critical it is to size a database well, split it up into multiple files and place it on performant disks.
Unsurprisingly, the same principles apply to tempdb. But from my time working at Microsoft it never ceased to amaze me how many clients went to a lot of trouble with the physical design of their application databases but paid no regard to applying the same principles to tempdb, so it would frequently be left on default settings in C:Program Files Microsoft SQL Serveretc etc.
But I don’t know how much IO my tempdb is doing
Tempdb performance and its IO load can be easily checked via the Microsoft SQL Server 2012 Performance Dashboard Reports as well as my posts on monitoring SQL Server IO.
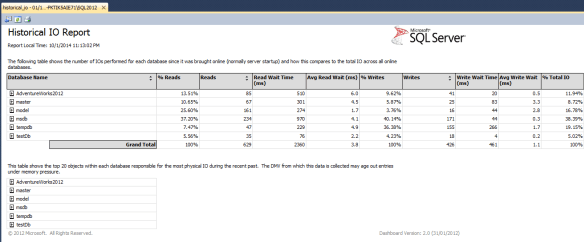
Figure 1: SQL Server tempdb overall IO throughput
Once the reports are installed, open up the main dashboard report and from there click on the Historical IO link. This takes you to the Historical IO Report, et voila! You can now see exactly how much IO your tempdb does in terms of reads, writes, the time taken to read and write and, crucially, the percentage of all IO that each database on that SQL Server instance is responsible for:
If tempdb is taking a significant percentage of that IO it makes sense to make sure it’s optimised as well as it can be.
For older versions of SQL Server check out this Codeplex project for dashboard reports that run from SQL Server 2005.
Sizes and stripes and trace flags
We know how much IO tempdb is doing and we want to apply the same tuning principles we would apply to any other database, starting with striping it across multiple files. There’s a lot of material out there on why this is ‘a good thing’ so I’m not going to regurgitate why here.
The first thing to check is that tempdb is not on default settings and in the default location (unless that default location has super-low latency and can handle a lot of IOPs).
Out of the box tempdb (up until at least SQL Server 2012) will be sized with one 8 MB data file and one 512 KB log file. If your SQL Server installation consists of one application database containing one table with one row then you’re good to go. The chances are your SQL Server installation will be a little more substantial than that so tempdb needs to be sized up.
In SSMS right-click on tempdb and select Properties and click on Files under the ‘Select a page’ section of the ‘Database Properties – tempdb’ dialog box:
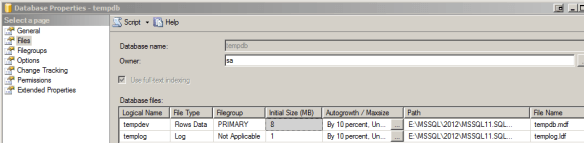
Figure 2: SQL Server tempdb file configuration
This will list the files, their location and initial sizes of tempdb. If there’s only one data and log file at the default sizes (under Initial Size (MB)) we have work to do. Note: the SSMS GUI will round-up a default log size of 512KB to 1MB. To prove this, run
sp_helpdb tempdb
in a new query window and review the output for the tempdb log file and it should show the size as 512MB.
Adding stripes is simply a question of clicking the Add button here and setting the appropriate size, autogrow, path and filename settings.
You’ll need to provision some fast storage for the additional tempdb stripes first. Ideally, use flash or SSDs or fast local disks. If you’re at the mercy of a SAN administrator, request something akin to RAID 0 as you don’t need to worry about mirroring/parity as tempdb is rebuilt on SQL Server startup. Obviously, if there’s a recurring issue it means there’s a disk problem so that will still need addressing, but from a DBA perspective there’s no recovery options for tempdb other than restarting SQL Server.
To work out how many stripes you need keep any eye on the guidance Microsoft publish as the advice changes over time. Anything I put down now will probably be out of date in a couple of years. I start at one quarter of the number of cores on the system if it has up to 64 cores and (personally) have never found the need to increase it beyond half the cores on systems with more than 32 cores.
On high throughput systems that are very tempdb heavy you may need to up this.
The SQLCAT team (or whatever they are called this month) recommend one stripe per core but these were extreme-scale systems so IMHO not practical for the vast majority of systems out there.
Establishing if you need more cores is not that difficult as this will manifest itself as something called PFS page contention.
Add stripes and enable trace flag 1118 as described in the above article and many others. There’s no downside to it and it’s a de facto step I take on all the SQL Server installations I’m involved with. Check out this Microsoft KB article if you’re still not sure.
The elephant in the room is the size of the stripes, and therefore the size of tempdb. There is no right answer for the size of tempdb. It depends on the load. The load is not necessarily how busy the system is right now, or even how busy it is at peak loads, it’s how big it needs to be when the most tempdb intensive loads are placed on it. E.g. overnight ETL jobs. If these jobs grow your tempdb to 500GB at 3am whereas for the previous 23 hours of every day your tempdb never has more than 50GB of data in it then your tempdb needs to be sized at 500GB in order to avoid autogrows which will cripple the performance of that overnight job as it incrementally autogrows to 500GB the next time it runs.
The same sizing principle applies to the transaction log file size; make it big enough to cope with the demands of the most intensive jobs to avoid autogrows.
In order to ensure the tempdb files grow evenly, trace flag 1117 should therefore be enabled.
[EDIT: as of SQL Server 2016 trace flags 1117 & 1118 do not need to be set at the server level as tempdb is automatically configured to behave this way.
It can now be set per database as documented at https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-traceon-trace-flags-transact-sql if required for user databases.
This article from the MS support team provides more information.]
There’s nothing to stop you looking at tasks that cause excessive tempdb (see the ‘Useful Links’ section at the end of this post) usage as there may be ways to optimise those tasks and reduce that tempdb usage, but sometimes we just have to accept that some of these procedures or jobs will just be heavy tempdb users so we divide our stripe sizes appropriately so they add up to the size of database that we need, plus a reasonable overhead both within the overall size of tempdb plus free space on the underlying volume the stripes reside on.
This leads inevitably onto the ‘how many volumes?’ question. Split the data files equally across multiple volumes is the simple answer, if it’s traditional spinning disks. If you’re fortunate enough to have flash storage which can handle anywhere from 300 to 500K IOPs one volume should suffice for most installations. If it’s a high throughput, latency sensitive system stripe across multiple flash devices. Besides, if tempdb is placed on a SAN (remember tempdb on local disks for a failover clustered instance of SQL Server is supported from SQL Server 2012) those multiple volumes you have requested might be placed on overlapping spindles anyway, or shared with other heavy usage systems, unless you happen to have a SAN admin who really knows their stuff (I think you’re more likely to stumble across a unicorn) or have the luxury of a dedicated SAN.
For failover cluster instances of SQL Server don’t forget to ensure that all the volumes and paths used for striping tempdb are present on all the nodes in the cluster, otherwise tempdb creation will fail and SQL Server will not come online on that node.
SQL Server will have to be restarted for any changes to the striping to take affect.
If SQL Server fails to start after these changes it’s almost always down to a typo in the path and that usually means having to force SQL Server to start with certain command line startup options as documented in this KB article. The article covers recovering a suspect tempdb but it shows what you need to do to restart SQL Server and bypass the creation of tempdb in order to get you into a position where tempdb paths can be corrected.
An aside: sometimes it really is worth finding out what’s using tempdb
On a system I used to manage we investigated tempdb usage as tempdb was generating a lot of slow IO warnings in the error log and the system was really struggling. The previously mentioned dashboard report revealed that 60% of all IO on the system was being generated by tempdb.
By checking the sys.dm_exec_requests DMV via some home-brewed stored procs (which I might one day blog about as they’ve proven very useful to me) and the use of Adam Machanic’s excellent sp_whoisactive proc we isolated the issue to one stored procedure that was doing some string manipulation and being called about 20 times a second. Not only that but it was explicitly creating and dropping a temp table whenever it was called.
The explicit tempdb creation and deletion was removed first and the string manipulation was eventually placed into a CLR function. Tempdb was then responsible for @ 10% of overall IO of the whole system. Not a difficult change and a big win on overall system performance and throughput.
So to summarise…
- use the dasboard reports or the blog posts summarised in my SQL Server and IO series of posts to get an idea of how tempdb is performing
- modify the tempdb configuration, if required, by carefully creating stripes with appropriate sizes and growth settings (don’t forget to test on every node if SQL Server is clustered)
- check the dashboard reports or DMVs and perfmon stats to get objective metrics on any improvments
- don’t forget to regularly review these metrics to ensure tempdb is coping
Useful links
Troubleshooting Insufficient Disk Space in tempdb